==============================================
In the fast-paced world of financial trading, accurate predictions are crucial for success. Traders rely on various tools and strategies to make informed decisions, and one such powerful tool is Random Forest. This machine learning algorithm has found its place in quantitative trading due to its ability to handle complex data and improve prediction accuracy. In this article, we will explore how Random Forest improves trading predictions, the benefits it offers, and how it stands out compared to other predictive models.
What is Random Forest?
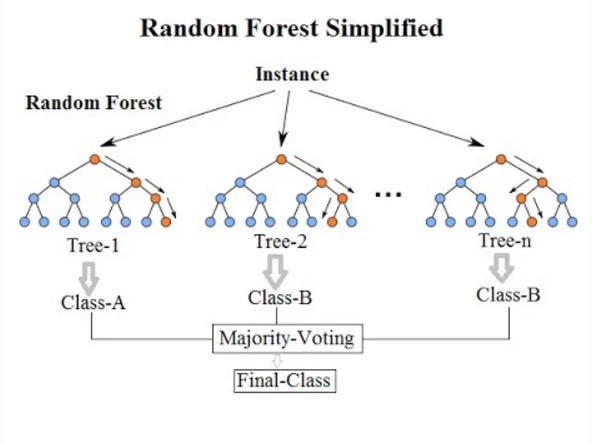
Random Forest is an ensemble machine learning algorithm that combines multiple decision trees to make predictions. The core idea is to train a collection of decision trees on different subsets of the data and then combine their outputs to arrive at a final decision. Each decision tree in the forest provides a vote, and the class or value that receives the majority of votes becomes the model’s prediction.
Why Use Random Forest for Trading Predictions?
The financial markets are inherently noisy and complex, which makes it challenging to predict price movements accurately. Random Forest’s ability to handle large datasets, reduce overfitting, and provide more reliable predictions makes it ideal for use in quantitative trading strategies. Here’s why it stands out:
- Robust to Overfitting: Unlike a single decision tree that may overfit the data, Random Forest reduces overfitting by averaging multiple trees, making the predictions more generalizable.
- Handles Missing Data: Random Forest can deal with missing data points effectively, which is crucial in real-world trading data where not all data points are complete.
- Feature Importance: Random Forest can provide insights into which features (e.g., technical indicators, trading volumes) are most important for making predictions, helping traders optimize their strategies.
How Random Forest Works in Trading
In trading, Random Forest models are used to predict asset prices, trends, volatility, and even market sentiment. These models take various market factors—such as past prices, trading volumes, volatility indices, and economic indicators—into account when making predictions.
Step 1: Data Preprocessing
Before using Random Forest in trading predictions, it’s important to preprocess the data. This involves:
- Collecting Data: Gathering historical market data (prices, volume, technical indicators, etc.) and any relevant economic factors.
- Feature Engineering: Creating new features (e.g., moving averages, RSI, MACD) that could help improve prediction accuracy.
- Handling Missing Values: Addressing missing or incomplete data using imputation or exclusion methods.
Step 2: Training the Model
Once the data is ready, the next step is to train the Random Forest model. The model is trained on a subset of the data, and different trees are created using various random combinations of features. This results in a diverse set of decision trees that each offer their own prediction.
Step 3: Making Predictions
After training, the model can be used to make predictions on new, unseen data. Random Forest will provide a final prediction based on the majority vote from all decision trees.
Step 4: Evaluation and Optimization
After predictions are made, the model’s performance is evaluated using various metrics such as accuracy, precision, recall, and F1-score. If necessary, the model is fine-tuned by adjusting hyperparameters (e.g., the number of trees, depth of the trees) to improve its performance.
Random Forest vs. Other Machine Learning Models in Trading
While Random Forest is highly effective in trading predictions, it’s important to understand how it compares to other popular machine learning models.
1. Random Forest vs. Decision Trees
- Random Forest: Uses multiple decision trees and combines their predictions, making it less prone to overfitting and improving prediction accuracy.
- Decision Trees: A single tree might overfit the data, which can lead to poor predictions when applied to new data.
Why Random Forest is Better:
- Improved Accuracy: Random Forest aggregates the predictions of multiple decision trees, leading to better overall accuracy.
- Robustness: By reducing overfitting, Random Forest provides more reliable predictions on unseen data compared to a single decision tree.
2. Random Forest vs. Neural Networks
- Neural Networks: A more complex model that uses layers of neurons to process data. Neural networks are very powerful, especially for unstructured data like images and texts.
- Random Forest: A simpler, more interpretable model, and less computationally expensive compared to neural networks.
Why Choose Random Forest:
- Less Computationally Intensive: Neural networks require more processing power and data for training. Random Forest can be run on smaller datasets and is easier to implement.
- Interpretability: Random Forest provides more transparency into feature importance, whereas neural networks are often considered “black boxes.”
3. Random Forest vs. Support Vector Machines (SVM)
- SVM: Effective in high-dimensional spaces but may struggle with large datasets and is sensitive to noise in the data.
- Random Forest: More scalable and robust to noise, making it suitable for large and complex trading datasets.
Why Random Forest is More Suitable:
- Scalability: Random Forest can handle large datasets better and is not as sensitive to noise as SVM.
- No Need for Feature Scaling: Unlike SVM, Random Forest does not require extensive preprocessing, such as feature scaling, which simplifies the implementation process.
Benefits of Using Random Forest in Trading
1. Enhanced Prediction Accuracy
Random Forest excels at handling complex data and providing more reliable predictions compared to other models. It is especially useful for identifying patterns in price movements, volatility, and other key market indicators.
2. Flexibility in Handling Different Data Types
Whether you’re working with price data, sentiment data, or fundamental factors, Random Forest can accommodate a wide variety of input data types, making it versatile for different kinds of trading strategies.
3. Feature Importance Insights
One of the key advantages of Random Forest is that it can identify which features (indicators, market conditions, etc.) are the most important for making predictions. This helps traders focus on the most impactful factors and optimize their strategies.
4. Resilience to Overfitting
Due to the ensemble nature of the model, Random Forest is less prone to overfitting compared to a single decision tree, making it more reliable for live trading situations.
How to Implement Random Forest for Trading
Step 1: Prepare the Data
- Gather historical data, including price, volume, and technical indicators.
- Clean the data by removing outliers and filling in missing values.
Step 2: Feature Engineering
- Create technical indicators like moving averages, Relative Strength Index (RSI), Bollinger Bands, etc., as features.
- Normalize the data if necessary.
Step 3: Train the Model
- Split the data into training and testing sets.
- Train the Random Forest model on the training data using appropriate parameters.
Step 4: Evaluate the Model
- Evaluate the model’s performance using metrics like accuracy, precision, and F1 score.
- Adjust hyperparameters (e.g., number of trees) to optimize the model.
Step 5: Deploy the Model for Live Trading
- Once the model is trained and optimized, it can be deployed for live predictions, continuously monitoring the market for trading opportunities.
FAQ: Common Questions about Random Forest in Trading
1. What are the key advantages of using Random Forest for trading predictions?
Random Forest’s ability to handle large datasets, its robustness against overfitting, and its ability to provide insights into feature importance make it a powerful tool for improving trading predictions.
2. Can Random Forest be used for high-frequency trading?
Yes, Random Forest can be used in high-frequency trading strategies, but it’s important to ensure that the model is trained on high-quality data with real-time processing capabilities.
3. How do I implement Random Forest for quantitative trading?
To implement Random Forest for quantitative trading, you need to collect and preprocess historical data, create relevant features, train the model, evaluate its performance, and then deploy it in a live trading environment.
Conclusion: Random Forest for Better Trading Predictions
Incorporating Random Forest into trading strategies can significantly improve the accuracy of predictions and provide traders with better insights into the market. By leveraging its ability to handle complex data, reduce overfitting, and offer transparency into feature importance, traders can make more informed decisions and optimize their strategies. Whether you are a beginner or an experienced trader, integrating Random Forest into your trading workflow can lead to more reliable and successful trades.