
================================================
Quantitative trading relies on data-driven models to make predictions and manage risks. Among the many machine learning algorithms, Random Forest has emerged as one of the most reliable and versatile tools. In this article, we’ll explore how to use Random Forest in quantitative trading, compare different implementation strategies, and share actionable tips for traders and analysts.
Understanding Random Forest in Quantitative Trading
What Is Random Forest?
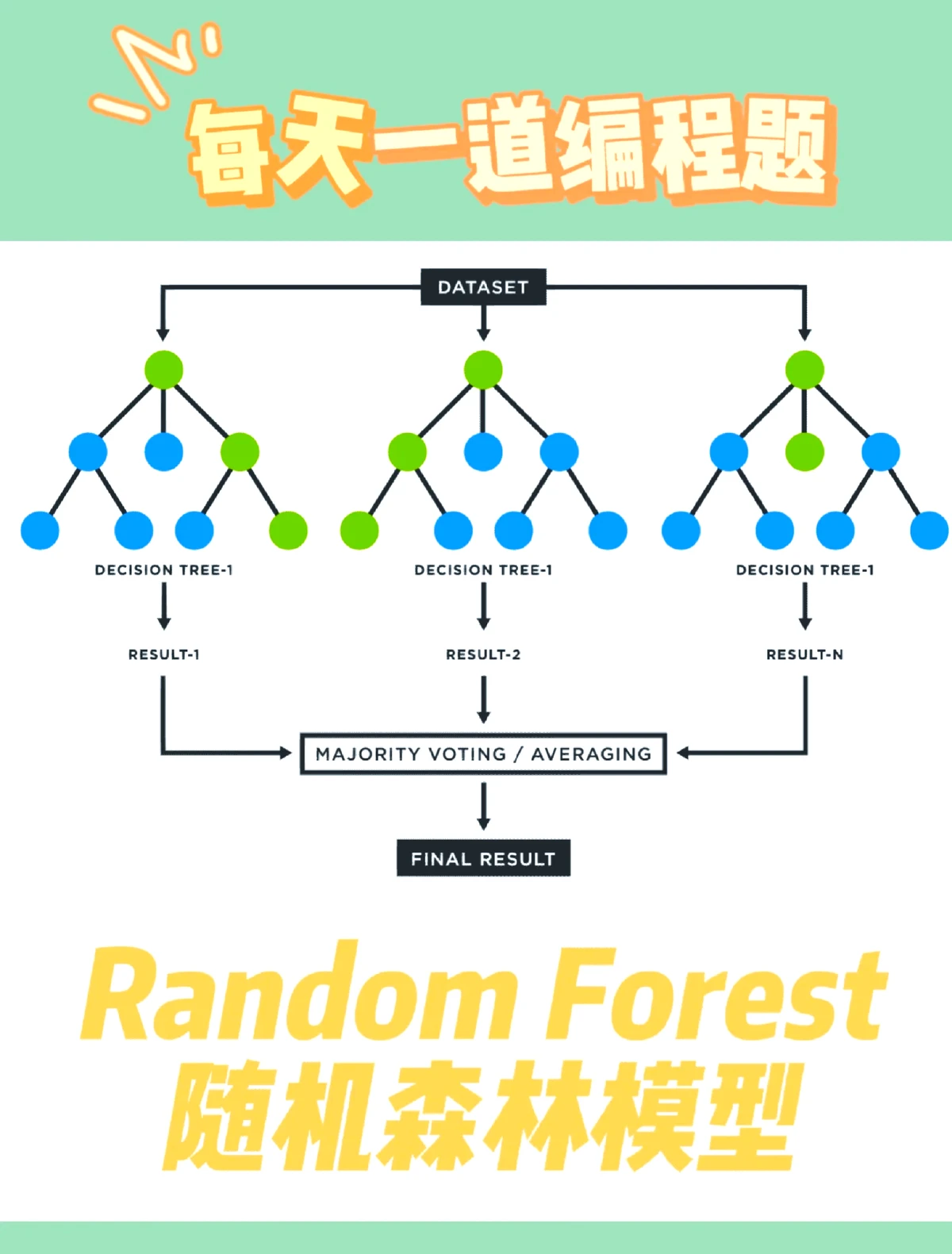
Random Forest is an ensemble learning algorithm that builds multiple decision trees and aggregates their outputs for more robust predictions. In quantitative trading, this translates into combining many weak models to produce a strong, reliable model that can better forecast market trends and reduce overfitting.
Random Forest workflow for trading
Why Random Forest Fits Quantitative Trading
Financial markets are noisy and complex. Random Forest can handle high-dimensional data (multiple indicators, timeframes, and assets) while mitigating overfitting. This gives traders a more stable prediction model compared to a single decision tree.
We can naturally embed concepts like how random forest improves trading predictions here, because its ability to average across multiple trees reduces prediction variance and leads to more accurate signals.
Preparing Data for Random Forest Models
Data Collection and Cleaning
A Random Forest model’s performance depends on data quality. Traders should collect historical price data, volume, order book information, and macroeconomic indicators. Outlier removal, normalization, and time alignment ensure the model receives clean input.
Feature Engineering for Trading
Random Forest models thrive on engineered features. Examples include:
- Lagged returns
- Moving averages
- Volatility metrics
- Sentiment indicators
By carefully designing features, quants can extract patterns not visible in raw data.
Feature engineering example in trading
Two Strategies for Using Random Forest in Quantitative Trading
1. Classification Approach
This method predicts discrete outcomes, such as “price will rise” vs. “price will fall.”
- Advantages: Clear trading signals, straightforward implementation.
- Disadvantages: Doesn’t directly estimate returns or probabilities.
2. Regression Approach
This predicts continuous values, such as next-period returns or volatility.
- Advantages: Produces more granular forecasts for position sizing.
- Disadvantages: Requires more sophisticated risk management to interpret predictions.
After comparing both, many hedge funds combine classification and regression for hybrid models. For example, they classify market regimes first and then apply regression to forecast returns within each regime.
Implementing Random Forest Step by Step
Step 1: Split Data into Training and Testing Sets
Always test your model on out-of-sample data to avoid overfitting.
Step 2: Choose Hyperparameters
- Number of trees
- Maximum tree depth
- Minimum samples per leaf
Hyperparameter tuning is critical. Automated search methods like grid search or Bayesian optimization can improve model performance.
Step 3: Model Evaluation
Use metrics like accuracy (for classification) or RMSE (for regression). In trading, also monitor Sharpe ratio, drawdowns, and hit rate.
Random Forest model evaluation metrics
Integrating Random Forest into Live Trading Systems
Backtesting
Before deploying, run extensive backtests to measure historical performance. Consider transaction costs and slippage.
Real-Time Execution
Implement efficient pipelines to feed live data into the model. Low latency can be crucial if strategies depend on short-term signals.
Monitoring and Maintenance
Random Forest models need regular retraining as market conditions change. Drift detection ensures your model stays relevant.
This naturally connects to random forest models for algo traders, who must deploy scalable systems that retrain and adapt quickly.
Pros and Cons of Using Random Forest in Trading
| Pros | Cons |
|---|---|
| Handles high-dimensional, nonlinear data well | Can be slower for very large datasets |
| Robust to overfitting | Less interpretable than single decision trees |
| Works with both classification and regression | May require extensive feature engineering |
| High accuracy for noisy financial data | Retraining needed as market regimes shift |
Recommended Best Practices
- Combine Random Forest with Other Models
Use ensemble methods or blend with gradient boosting or deep learning to improve performance.
- Monitor Model Drift
Set up alerts when the model’s performance metrics degrade.
- Start Simple, Then Scale
Begin with a small number of trees and features; scale up as you gain confidence.
FAQ: Random Forest in Quantitative Trading
1. How does Random Forest differ from decision trees in trading?
A single decision tree can overfit to market noise. Random Forest combines multiple trees, averaging their predictions, which stabilizes the model and improves out-of-sample performance.
2. Why choose Random Forest for trading over other machine learning methods?
Random Forest is robust, easy to implement, and works well with both structured and unstructured data. It often outperforms more complex models when data is limited or highly noisy.
3. How to optimize Random Forest for trading?
Adjust the number of trees, depth, and feature selection. Also, retrain regularly to capture new market dynamics and test multiple feature sets to identify the most predictive signals.
Conclusion and Call to Action
Random Forest is one of the most practical machine learning tools for quantitative trading. Its ability to handle noisy, high-dimensional data and produce stable predictions makes it attractive to quants, hedge funds, and individual traders alike. Whether you’re just starting with random forest methods for quants or running a professional algo-trading desk, this model offers flexibility and power.
If you found this guide useful, share it with your peers, comment below with your experiences using Random Forest in trading, and subscribe for more actionable quantitative trading insights!