

========================================================
The rise of machine learning has transformed quantitative trading. Among the most widely used models are decision trees and their ensemble counterpart, random forests. While both methods originate from the same foundation, their application in financial markets differs significantly. Understanding how random forest differs from decision trees in trading is crucial for traders, analysts, and quants looking to refine their strategies with data-driven insights.
This article explores the mechanics, advantages, disadvantages, and practical applications of both models in trading, compares their performance, and highlights why random forest is often considered superior in real-world scenarios.
Understanding Decision Trees in Trading
What Are Decision Trees?
A decision tree is a flowchart-like structure where data is split into branches based on conditions. Each internal node represents a test (e.g., price > moving average), each branch represents the outcome, and each leaf node represents a decision (e.g., buy, sell, hold).
In trading, decision trees are often used for pattern recognition, signal classification, and risk analysis.
Strengths of Decision Trees in Trading
- Interpretability: Easy to understand and explain to traders and investors.
- Low computational cost: Can be quickly trained on medium-sized datasets.
- Feature selection: Automatically identifies which variables (indicators, ratios, or price features) are most relevant.
Weaknesses of Decision Trees in Trading
- Overfitting: A major drawback. Trees can fit historical data too closely, leading to poor generalization on unseen market conditions.
- Instability: Small changes in data can produce a completely different tree.
- Limited predictive power: Single trees often fail in noisy, high-dimensional trading data.
Understanding Random Forests in Trading
What Are Random Forests?
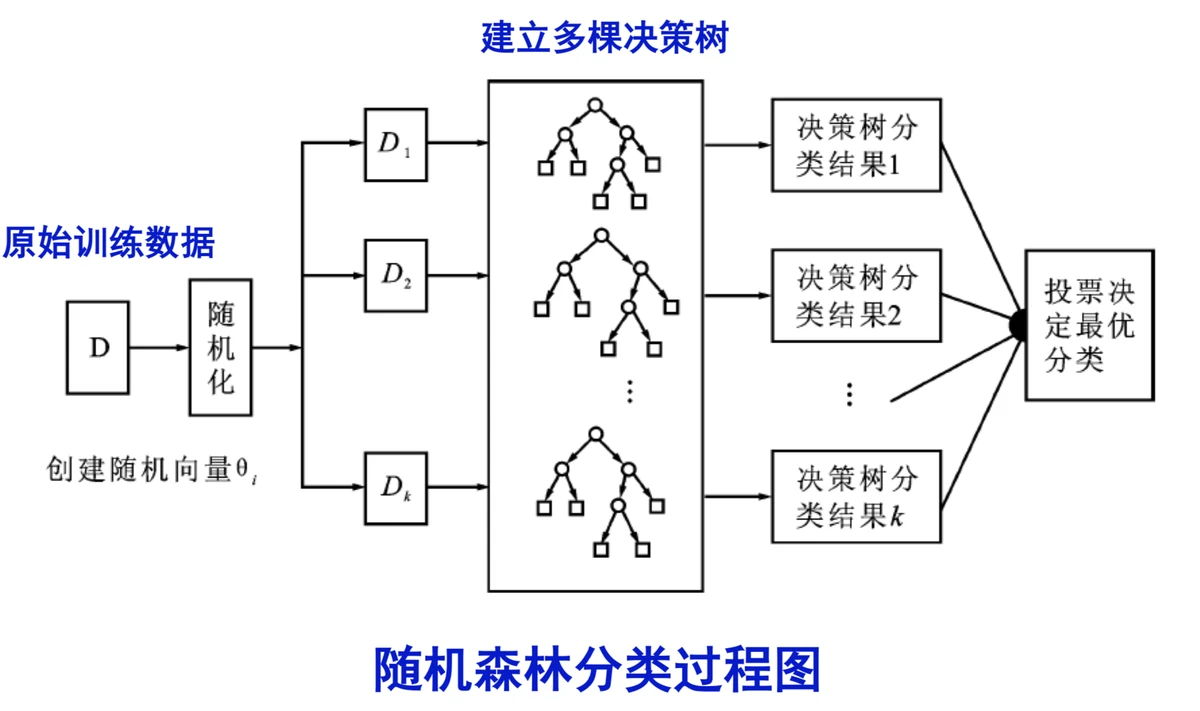
Random forest is an ensemble method that builds multiple decision trees on random subsets of data and features. The final prediction is made by aggregating the outputs (e.g., majority voting for classification or averaging for regression).
In trading, random forests are used to predict price direction, classify market regimes, or estimate risk-adjusted returns.
Strengths of Random Forests in Trading
- Reduced overfitting: By averaging multiple trees, random forest smooths out noise.
- Better generalization: Works well on complex, noisy datasets typical in financial markets.
- Feature robustness: Handles correlated indicators and redundant features effectively.
- Versatility: Useful for regression (predicting returns) and classification (predicting up/down moves).
Weaknesses of Random Forests in Trading
- Less interpretability: Harder to explain compared to a single decision tree.
- Computationally intensive: Training hundreds of trees can be resource-heavy.
- Black-box nature: Traders may find it challenging to justify trades purely based on aggregated votes.
Decision trees are simple and interpretable, while random forests enhance robustness and accuracy by combining multiple trees.
Key Differences Between Random Forest and Decision Trees in Trading
1. Overfitting Control
- Decision Tree: Prone to overfitting historical price movements.
- Random Forest: Mitigates overfitting by aggregating multiple models, improving stability.
2. Predictive Accuracy
- Decision Tree: Adequate for basic strategies but struggles with market noise.
- Random Forest: Excels in predictive power, particularly in high-frequency or multi-asset strategies.
3. Feature Handling
- Decision Tree: May overemphasize certain technical indicators.
- Random Forest: Distributes importance across features, making it more balanced.
4. Use Case Suitability
- Decision Tree: Best for quick prototyping, explainability, and educational purposes.
- Random Forest: Best for production-level trading models requiring robustness and accuracy.
Strategies Using Decision Trees vs Random Forests
A. Decision Tree Strategy: Trend Classification
Traders may use decision trees to classify markets into trending vs. non-trending phases using indicators like RSI, MACD, and moving averages.
- Pros: Transparent, easy to implement.
- Cons: Highly sensitive to noise, may fail in volatile conditions.
B. Random Forest Strategy: Multi-Factor Signal Prediction
Random forests can integrate dozens of features such as sentiment scores, volatility measures, order book depth, and technical indicators to predict price movements.
- Pros: Robust against noise, captures non-linear relationships.
- Cons: Requires more computational power and hyperparameter tuning.
Personal Insights and Industry Trends
From experience working with algorithmic trading teams, decision trees are often used as teaching tools or model prototypes, but they rarely survive in production trading environments. Random forests, however, are actively deployed in hedge funds and quant firms, especially in equity factor modeling and short-term predictive analytics.
The latest trend is combining random forests with deep learning for hybrid models, where forests handle feature importance and neural networks capture sequential patterns.
Workflow of using random forest in trading: feature engineering, ensemble training, prediction, and risk control.
Related Insights
When exploring further, it is worth learning how to use random forest in quantitative trading and how random forest improves trading predictions. These complementary topics provide deeper guidance for traders looking to deploy machine learning in real-world strategies.
FAQs on Random Forest vs Decision Trees in Trading
1. Why should I use random forest instead of decision trees in trading?
Random forest is generally more reliable because it reduces overfitting, improves accuracy, and handles noisy trading data better. Decision trees are easier to interpret but less robust.
2. Can decision trees still be useful in trading?
Yes, they are useful for prototyping, feature selection, and educational purposes. However, for actual deployment, random forests or other ensemble models are usually superior.
3. How do I optimize random forest for trading performance?
Key steps include tuning the number of trees, maximum depth, and feature sampling. Cross-validation on rolling windows of market data helps prevent overfitting to a single regime.
Conclusion: Choosing the Right Model
Understanding how random forest differs from decision trees in trading highlights that while decision trees offer simplicity and interpretability, random forests deliver accuracy, robustness, and reliability in real-world markets.
For traders seeking production-ready models, random forest is the clear choice. Decision trees remain valuable as a conceptual tool and a stepping stone to more advanced ensemble methods.
If this guide gave you clarity, share it with your trading community, comment with your experiences, and join the discussion on machine learning in finance.
Would you like me to extend this with Python code examples showing backtests of decision trees vs random forests on real trading data to make it even more actionable?