
Support Vector Machines (SVM) have long been a cornerstone of machine learning, especially for those dealing with complex, high-dimensional datasets. As the field evolves, experts continue to refine and enhance SVM techniques, making them even more applicable to advanced domains such as finance, computer vision, and natural language processing. In this article, we’ll delve into advanced support vector machine (SVM) techniques for experts, explore the latest trends in their use, and provide insights on how to optimize and fine-tune these models for better performance in real-world scenarios.
What is Support Vector Machine (SVM)?
Overview of Support Vector Machine
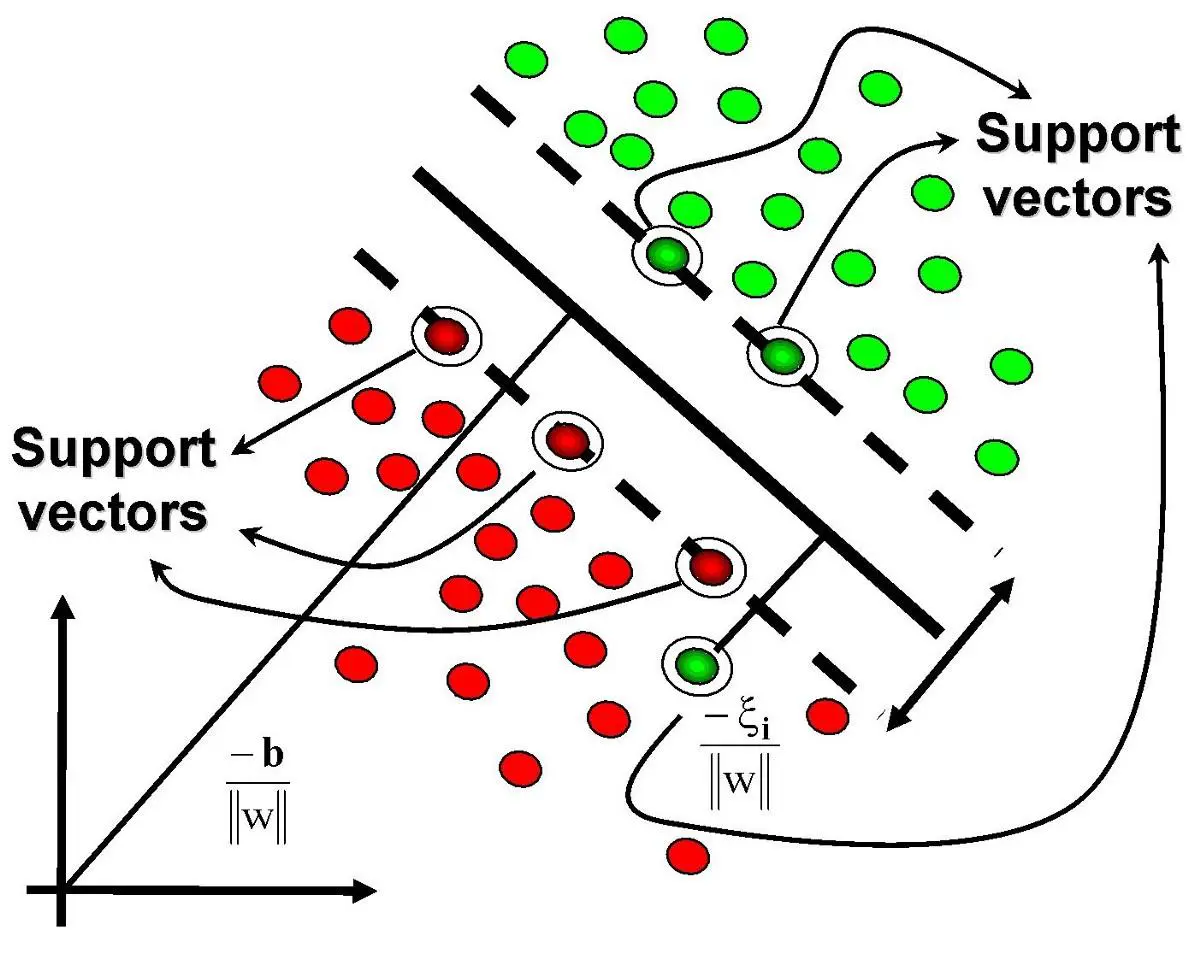
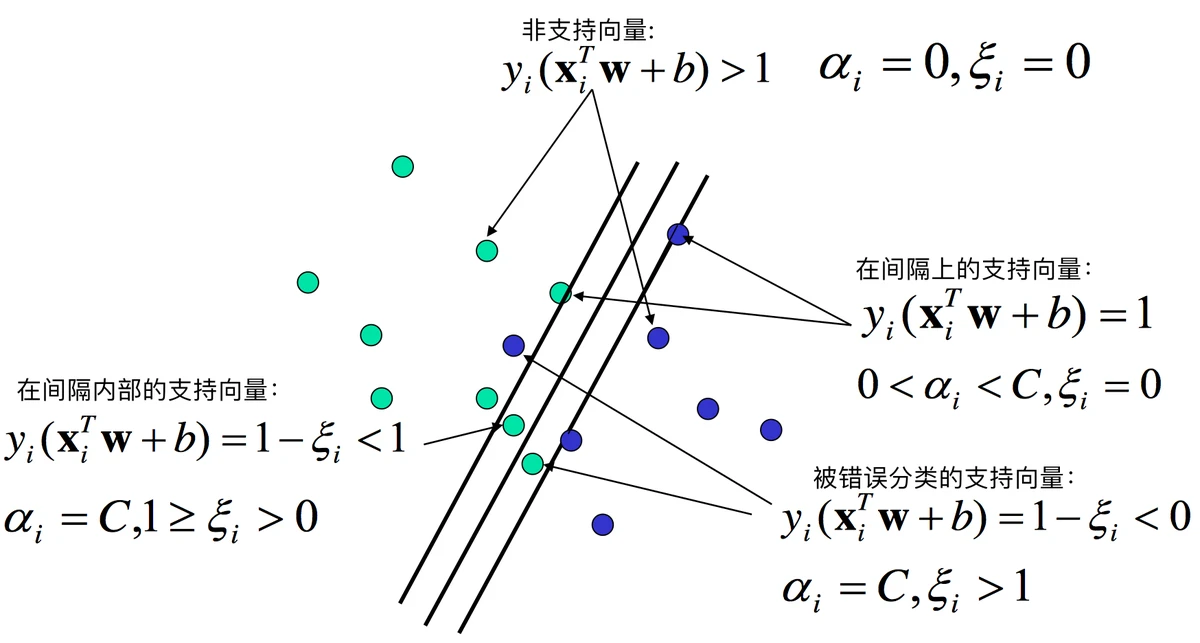
Support Vector Machine is a supervised learning algorithm used primarily for classification and regression tasks. SVM works by finding the hyperplane that best separates data points of different classes while maximizing the margin between them. The points that are closest to this hyperplane are known as support vectors, and they play a crucial role in determining the optimal hyperplane.
In its simplest form, SVM works in two-dimensional space to separate classes of data, but it can be extended to higher dimensions using the kernel trick.
The Power of SVM in Advanced Applications
While basic SVM is powerful, its true potential is realized when leveraging advanced techniques, such as non-linear kernels, multi-class classification, and SVM for regression (SVR). These methods allow SVM to be used in more complex, real-world problems.
Advanced SVM Techniques for Experts
- Non-linear Kernels
In the real world, data is rarely linearly separable. This is where non-linear kernels come into play. A kernel function maps the input data into a higher-dimensional space, enabling the SVM to find non-linear boundaries that better separate classes.
Popular Kernel Functions
Radial Basis Function (RBF) Kernel: Often used due to its ability to handle non-linear relationships in the data.
Polynomial Kernel: Suitable for data with a polynomial decision boundary.
Sigmoid Kernel: Inspired by neural networks, the sigmoid kernel can map data to a hyperbolic tangent space.
- Multi-class Classification with SVM
While basic SVM can handle binary classification, real-world problems often involve more than two classes. SVM techniques for multi-class classification allow the model to classify data into more than two categories. The most popular approaches to multi-class SVM are:
One-vs-One (OvO): This method involves training a classifier for every possible pair of classes. If there are n classes, the number of classifiers is n(n-1)/2.
One-vs-All (OvA): Here, one classifier is trained for each class, where the target class is marked as positive, and all other classes are treated as negative. The classifier with the highest score is chosen.
- SVM for Regression (SVR)
Support Vector Regression (SVR) is an extension of SVM that performs regression tasks. SVR attempts to find a function that deviates from the actual data points by a margin of error and performs better than other regression models for non-linear data. SVR is particularly useful in predicting financial markets, stock prices, and any continuous data patterns.
Key Concepts in SVR:
Epsilon Tube: SVR tries to minimize the error within a specified threshold (epsilon tube) instead of forcing the data points to fall exactly on the regression line.
Kernel Function: SVR also uses kernels, allowing it to work in high-dimensional spaces.
- Feature Selection and Optimization
In any machine learning model, feature selection plays a pivotal role in improving model performance. For SVM, selecting the right features is crucial since SVM can suffer from overfitting when the input feature set is too large or irrelevant. Advanced SVM techniques involve:
Recursive Feature Elimination (RFE): A method that iteratively removes the least significant features to improve model accuracy.
Hyperparameter Tuning: Techniques like grid search and random search to optimize the SVM hyperparameters such as C (penalty parameter) and gamma (kernel coefficient).
- Outlier Detection Using SVM
Outlier detection is essential in many data analysis scenarios, especially in fields like finance and cybersecurity. One-Class SVM is a special version of SVM designed specifically for identifying outliers in data. It works by learning a decision function for an unknown class, assuming that the majority of the data points belong to one class (the “normal” class), and anything that deviates significantly from this class is considered an outlier.
Applications of Advanced SVM Techniques
- Algorithmic Trading and Quantitative Finance
SVM techniques have found significant applications in algorithmic trading and quantitative finance. In these fields, SVMs are used to predict stock prices, market trends, and asset volatility. SVM for trading can outperform traditional models by capturing non-linear relationships and incorporating complex features such as moving averages, trading volume, and sentiment analysis.
- Image Recognition and Computer Vision
SVMs, particularly with RBF kernels, are extensively used in computer vision for image classification and recognition. The ability of SVM to map data into high-dimensional spaces makes it ideal for handling pixel-based features in images.
- Natural Language Processing (NLP)
In NLP, SVM is used for text classification tasks such as sentiment analysis, spam detection, and topic classification. TF-IDF (Term Frequency-Inverse Document Frequency) is often used as a feature representation in SVM for processing large text datasets.
Comparison of Advanced SVM Techniques
Technique Pros Cons Best Use Case
Non-linear Kernels Handles complex decision boundaries Computationally expensive Complex data with non-linear separability
Multi-class SVM Effective for multi-class classification Requires more classifiers (OvO or OvA) Multi-class classification problems
SVR (Support Vector Regression) Effective for non-linear regression problems Sensitive to noise and outliers Predicting continuous values
Outlier Detection Identifies anomalies effectively Limited to identifying rare cases Fraud detection, anomaly detection
FAQ on Advanced SVM Techniques for Experts
- What are the key hyperparameters to tune in SVM?
The primary hyperparameters in SVM include:
C (Regularization Parameter): Controls the trade-off between maximizing the margin and minimizing classification error. A higher C emphasizes fewer misclassifications, while a lower C allows more flexibility.
Gamma (Kernel Coefficient): Controls the shape of the decision boundary in the kernel. A large gamma can lead to overfitting, while a small gamma can lead to underfitting.
Kernel Type: Choose between linear, polynomial, RBF, or sigmoid kernels based on the data’s nature.
- How do I prevent overfitting in SVM?
Overfitting in SVM can be mitigated by:
Using the C parameter carefully, as a very high value might lead to overfitting.
Selecting relevant features and applying feature scaling (e.g., standardization or normalization).
Using cross-validation techniques to assess the model’s performance and avoid fitting to noise.
- How can I implement advanced SVM techniques in Python?
To implement advanced SVM techniques in Python, you can use the scikit-learn library, which provides efficient implementations of SVM and SVR. Here’s an example of setting up an SVM with RBF kernel:
python
Copy code
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
Load dataset
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
Initialize SVM with RBF kernel
svm_model = SVC(kernel=‘rbf’, C=1, gamma=‘scale’)
Train the model
svm_model.fit(X_train, y_train)
Evaluate the model
print(svm_model.score(X_test, y_test))
Conclusion
| Category | Details | Tools/Methods | Pros | Cons | Best Use Cases |
|---|---|---|---|---|---|
| Comprehensive Crypto Trading Analysis | Integration of technical, quantitative, and behavioral analysis for holistic decision-making. | Technical Analysis, Quantitative Models, Sentiment Analysis | Improves win rates, risk management, and mitigates systemic risks. | Complexity in combining multiple methods, potential data overload. | All types of traders (retail, institutional). |
| Technical Analysis (TA) | Uses price charts, patterns, and indicators to predict market movements. | Moving Averages (MA & EMA), RSI, Ichimoku Cloud, Candlestick Patterns | Easy to implement, highly visual, works well for liquid assets like Bitcoin and Ethereum. | Subjective interpretation, false signals in low-liquidity markets. | Short-term swing or day trading. |
| Quantitative & Algorithmic Analysis | Data-driven models and automated strategies, mainly used by professionals and hedge funds. | Statistical Arbitrage, Momentum Strategies, Machine Learning, Risk-Parity, Portfolio Optimization | Objective, data-driven, scalable for high-frequency trading, processes large datasets. | Requires coding skills, expensive infrastructure, susceptible to overfitting. | Institutional strategies, high-frequency trading. |
| Behavioral & Sentiment Analysis | Analyzes market psychology, crowd behavior, and news sentiment. | Natural Language Processing (NLP), Fear & Greed Index, On-chain Metrics (active wallet addresses, transaction volumes) | Provides insight into trader behavior, useful in volatile markets. | Difficult to quantify sentiment, influenced by noise and rumors. | Volatile market conditions, short-term price movement. |
| Comparing Technical vs Quantitative | Technical analysis is more accessible and manual, whereas quantitative analysis requires coding and is fully automated. | - | TA is beginner-friendly, quantitative is scalable for advanced trading. | TA is subjective; quantitative is prone to overfitting. | TA for beginners, quantitative for advanced traders. |
| Risk Management in Crypto | Essential in comprehensive analysis. Ensures trades are properly sized and protected with stop-losses and profit-taking mechanisms. | Position Sizing based on volatility, Stop-Loss and Take-Profit Orders, Correlation Checks | Protects capital, mitigates losses, improves consistency in trades. | Requires continuous monitoring and adjustment. | All crypto traders. |
| Platform & Tools for Analysis | Tools and platforms to execute comprehensive analysis efficiently. | TradingView, Coinigy (TA), Python libraries (Pandas, TensorFlow) for quant models, Glassnode (on-chain metrics), Freqtrade, CCXT API for bot execution. | Variety of tools for both TA and quantitative models, accessible to all traders. | Advanced users require more complex setups, beginners may find it overwhelming. | Beginners to advanced traders, algorithmic traders. |
| Practical Application | Combining TA and quant models to improve trade success and using risk management as the foundation. | Example: RSI + Quantitative Momentum Models, Volatility-Based Position Sizing | Increases probability of successful trades, integrates risk control. | Need to validate combined strategies and ensure consistent results. | Traders looking to validate trade signals. |
| Case Study: Bitcoin Volatility | Example of a bull run in 2020-2021; analysis of Bitcoin’s price movements during the pandemic. | EMA Crossovers (TA), Volatility-Adjusted Allocation (Quant Models), Institutional Sentiment (Sentiment Analysis) | Multi-layered approach helped navigate volatility, manage bull runs, and corrections. | High volatility still presents risk, difficult to anticipate all market changes. | Traders navigating volatile market cycles. |
| FAQ | Common questions regarding crypto trading analysis methodologies. | - | Clarifies approach for beginners and professionals, emphasizes hybrid strategies. | None directly addressed, mainly guidance for tool selection and strategy. | Beginners and professional traders. |
0 Comments
Leave a Comment