
====================================================

Introduction
Machine learning has become a cornerstone of modern quantitative finance. For trading beginners, one of the most practical and approachable algorithms to start with is the Random Forest. This ensemble learning technique combines multiple decision trees to improve prediction accuracy and reduce overfitting. In trading, Random Forest can be applied to forecast price movements, classify market regimes, or enhance risk management.
This guide provides a step-by-step explanation of how to implement Random Forest for trading beginners, integrating professional insights, real-world applications, and hands-on examples. We’ll explore two practical methods, compare their pros and cons, and explain how to integrate Random Forest into a trading workflow.
By the end, you’ll understand not just the mechanics of Random Forest, but also how to apply it effectively in trading, and where it fits in the broader landscape of quantitative strategies.

What Is Random Forest in Trading?
Definition
Random Forest is an ensemble machine learning algorithm that builds multiple decision trees and averages their predictions (for regression) or uses majority voting (for classification). In trading, it can predict future price movements, volatility, or even asset allocation decisions.
Why Random Forest Is Useful for Beginners
- Handles noisy data: Financial markets are noisy, but Random Forest can capture patterns without overfitting too quickly.
- Feature importance: It shows which market indicators (technical or fundamental) drive predictions.
- Scalability: Works on both small and large datasets, making it flexible for beginner and professional traders.
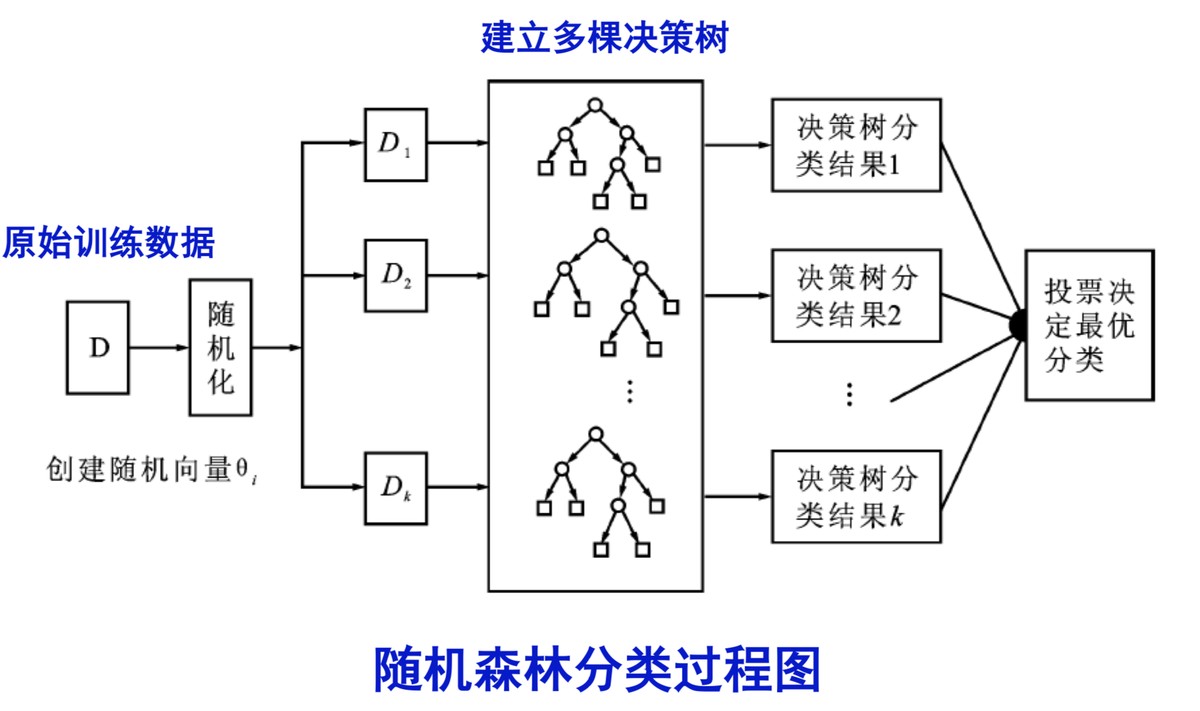
How Does Random Forest Model Work in Trading?
Random Forest works by building a forest of decision trees, each trained on random subsets of data and features. The diversity among trees makes the model more robust.
In trading:
- Input features can be technical indicators (moving averages, RSI, MACD), price returns, or order book data.
- Each decision tree produces a prediction: e.g., whether tomorrow’s return will be positive or negative.
- Random Forest aggregates these predictions to make a final decision.
This makes Random Forest particularly strong in environments where single decision trees would overfit.
Step-by-Step: How to Implement Random Forest for Trading Beginners
Step 1: Collect Data
Beginners should start with freely available data such as daily price history for Bitcoin, Ethereum, or equities. Historical OHLCV (Open, High, Low, Close, Volume) data is a good foundation.
Step 2: Feature Engineering
Generate indicators such as:
- Moving Averages (SMA, EMA)
- Relative Strength Index (RSI)
- Bollinger Bands
- Daily returns and volatility measures
Step 3: Split Data
Divide your dataset into training (70%) and testing (30%) to evaluate model performance fairly.
Step 4: Train the Random Forest
Using Python’s scikit-learn library:
python
Copy code
from sklearn.ensemble import RandomForestClassifier
fr
0 Comments
Leave a Comment