
=========================================
In the ever-evolving landscape of algorithmic trading, machine learning models are increasingly being adopted to enhance predictive accuracy and risk-adjusted returns. Among these models, the Random Forest algorithm stands out due to its robustness, ability to handle non-linear relationships, and resilience against overfitting. But to achieve consistently profitable results, traders need to understand how to optimize Random Forest for trading. This guide will explore effective strategies, practical techniques, and the latest industry insights to help quants, algo traders, and portfolio managers fully harness the power of Random Forest.
Understanding Random Forest in Trading
What is Random Forest?
Random Forest is an ensemble learning method that builds multiple decision trees during training and outputs the average prediction (for regression tasks) or majority vote (for classification tasks). In trading, it is often used to forecast price movements, identify market regimes, and generate buy/sell signals.
Why Random Forest is Effective for Trading
- Handles noisy market data: Market data is often unstructured and volatile. Random Forest can handle noise better than single decision trees.
- Feature importance ranking: It allows traders to identify which technical indicators, macroeconomic factors, or sentiment signals truly influence returns.
- Avoids overfitting: By aggregating multiple trees, Random Forest reduces variance, leading to more stable performance in live trading.
For example, when compared to single models, how random forest improves trading predictions becomes evident in environments with high variance, such as intraday crypto trading or FX markets.
Key Optimization Techniques for Random Forest in Trading
Optimizing Random Forest is not just about fine-tuning hyperparameters. It involves a blend of data engineering, model calibration, and trading-specific adjustments.
1. Hyperparameter Tuning
- Number of trees (n_estimators):
Increasing the number of trees improves accuracy but raises computational costs. For trading, a balance is needed to ensure timely execution.
Optimal range: 200–500 trees for intraday models, 500–1000 for longer-term models.
- Maximum depth of trees (max_depth):
Shallow trees may underfit, while deep trees may overfit. In trading, setting depth between 5–15 often provides robust performance.
- Maximum features (max_features):
Controls how many features are considered at each split. For financial data with correlated variables, “sqrt” or “log2” settings often prevent redundancy.
- Minimum samples per leaf/node:
A higher minimum can reduce overfitting and ensure that trading signals are based on broader market behavior rather than anomalies.
2. Feature Engineering
- Lagged returns & volatility indicators: Incorporating features like moving averages, Bollinger Bands, and RSI often boosts predictive power.
- Market microstructure data: Order book imbalances, bid-ask spreads, and liquidity factors can significantly enhance signal accuracy.
- Regime-switching indicators: Random Forest performs better when trained on datasets segmented by volatility regimes or macroeconomic conditions.
3. Model Validation
- Walk-forward analysis: Instead of static train-test splits, rolling windows better reflect real trading conditions.
- Cross-validation with time series splits: Prevents data leakage and provides more realistic performance expectations.
- Out-of-sample backtesting: Ensures strategies hold up across different market cycles.
Two Approaches to Optimization: Hyperparameter Tuning vs. Feature Selection
Hyperparameter Tuning
- Advantages: Directly improves model accuracy and reduces overfitting.
- Drawbacks: Computationally intensive; may not generalize if market conditions shift.
Feature Selection
- Advantages: Simplifies model, improves interpretability, reduces noise.
- Drawbacks: Risk of excluding weak but useful predictors in certain regimes.
👉 The best practice is to combine both: tune hyperparameters while simultaneously pruning irrelevant features.
Industry Trends in Random Forest for Trading
- Integration with Deep Learning
Many quants now combine Random Forest with neural networks, using Random Forest for feature importance ranking and neural nets for signal generation.
- Real-Time Optimization
With high-frequency trading, Random Forest models are being optimized using streaming data pipelines to adapt to intraday volatility.
- Hybrid Risk Models
Hedge funds often use Random Forest not just for signal generation but also for risk management, such as detecting portfolio drawdown risks.
Practical Example: Optimizing Random Forest for Equity Trading
Imagine a trader building a Random Forest model to predict S&P 500 futures movements. The steps might include:
- Data preparation: Include lagged returns, implied volatility (VIX), and macro indicators (interest rate spreads).
- Feature selection: Use Random Forest’s built-in feature importance to drop redundant technical indicators.
- Hyperparameter tuning: Apply Bayesian optimization to tune
n_estimators,max_depth, andmin_samples_split.
- Walk-forward testing: Validate across 2008 crisis, 2020 COVID crash, and recent inflation-driven volatility to ensure robustness.
This approach ensures that the model is not curve-fitted but adaptable across different market regimes.
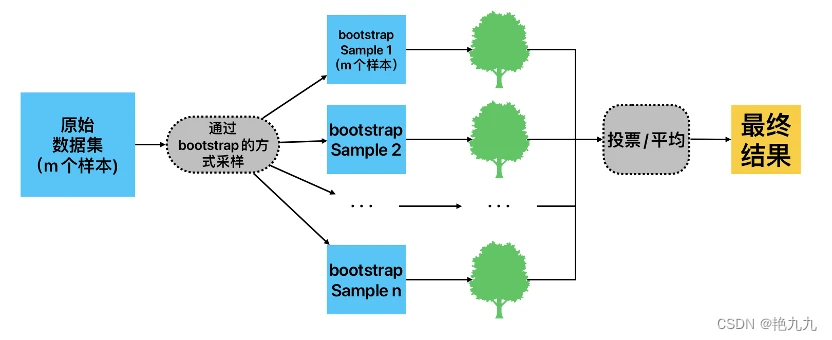
Visualization of Random Forest Optimization
Random Forest optimization process for trading
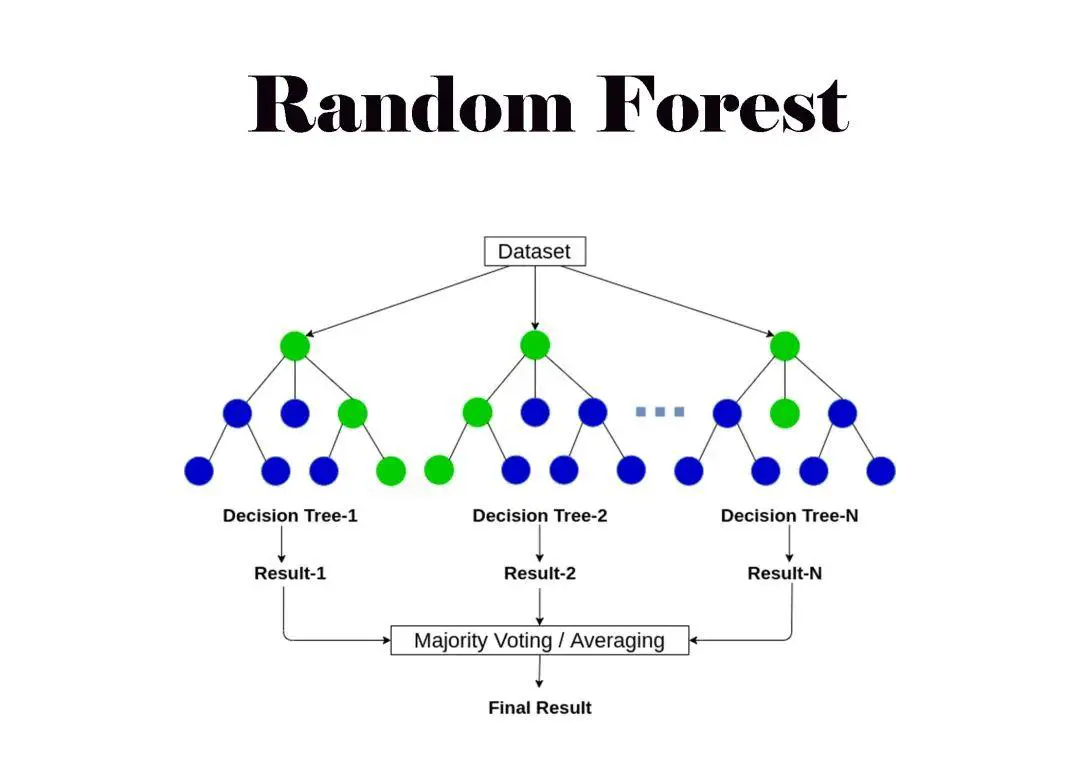
Integrating Random Forest with Trading Strategies
Random Forest is not a standalone solution—it must integrate with execution and risk frameworks.
- Signal-to-execution pipeline: Random Forest predicts signals; execution algorithms handle order routing and slippage minimization.
- Portfolio allocation: Predictions can be combined with mean-variance optimization or Kelly criterion for capital allocation.
- Hedging applications: Random Forest can support advanced techniques like how to use random forest in quantitative trading, particularly in constructing delta-neutral or volatility-driven strategies.
Common Mistakes to Avoid
- Overfitting historical data: Leads to strong backtests but poor live performance.
- Ignoring transaction costs: Even accurate signals can fail once costs are included.
- Lack of regime awareness: A model trained on bull markets may fail during crashes.
- Blind reliance on feature importance: Financial variables interact non-linearly; dropping weak predictors may harm performance.
FAQ: Random Forest Optimization in Trading
1. What hyperparameters matter most when optimizing Random Forest for trading?
The most impactful are n_estimators, max_depth, and max_features. Traders should also adjust min_samples_split to avoid overfitting to short-term anomalies. Using Bayesian optimization or grid search is recommended.
2. How does Random Forest compare to other ML models in trading?
Random Forest offers more stability than neural networks in smaller datasets and is easier to interpret. However, neural nets may outperform in high-frequency crypto or FX where nonlinearities dominate. Many funds now combine the two for better results.
3. Can Random Forest adapt to changing market regimes?
Yes, but only if you implement walk-forward optimization and retrain models frequently. Random Forest is less adaptive than online learning models, but regime segmentation can make it resilient.
Conclusion
Optimizing Random Forest for trading requires a structured approach: feature engineering, hyperparameter tuning, walk-forward validation, and integration with execution systems. While both hyperparameter tuning and feature selection offer unique benefits, the most reliable strategies blend the two. Random Forest’s versatility makes it a powerful tool for quants, hedge funds, and retail algo traders, provided it is applied with discipline and tested rigorously.
If you found this guide useful, share it with fellow traders, data scientists, or colleagues exploring machine learning in finance. Let’s discuss in the comments—what Random Forest optimization techniques have worked best in your trading journey?
0 Comments
Leave a Comment